CS205 Final Project
Cooper Lorsung • Sujay Thakur • Royce Yap • David Zheng
Results and Discussion
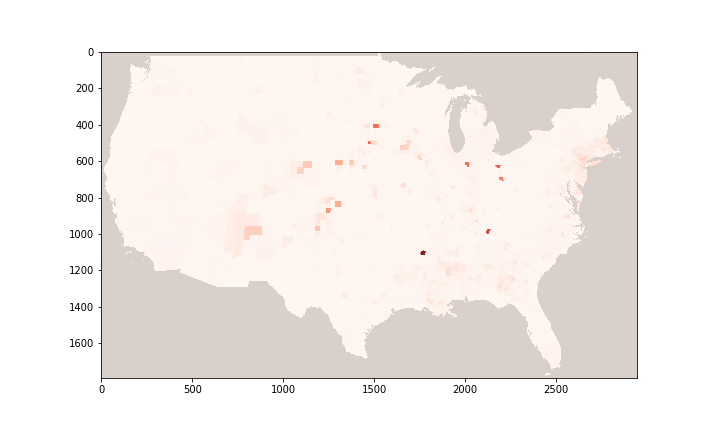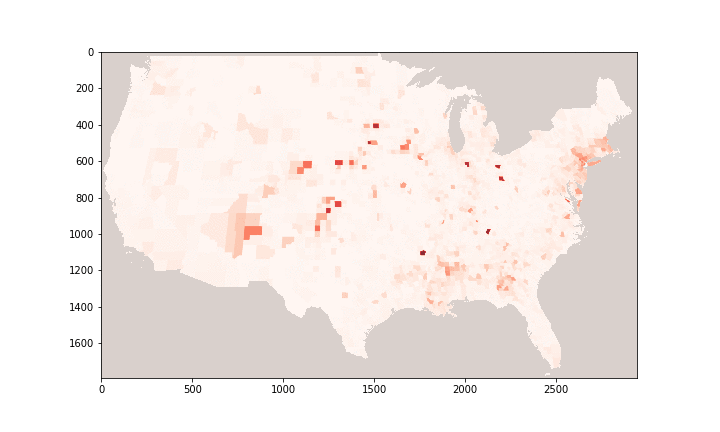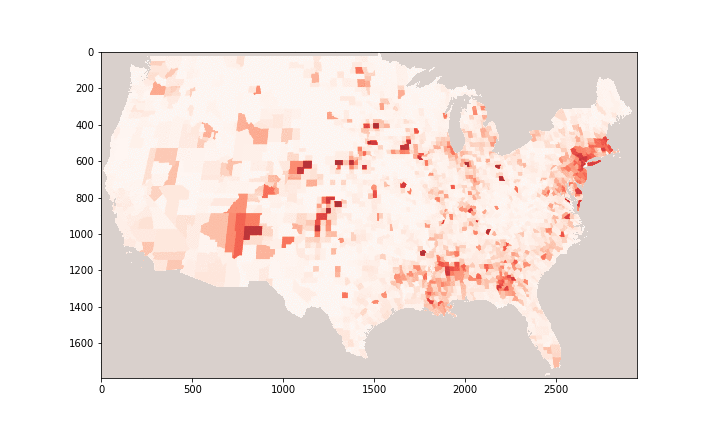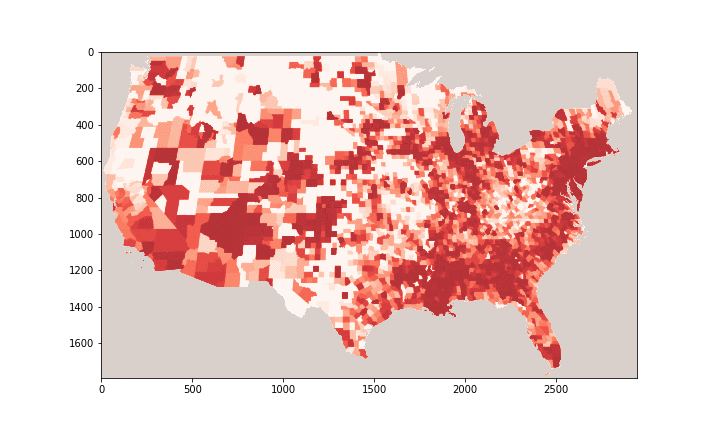
Performance evaluation
Speedup can be seen to increase with number of cores for both AWS and Odyssey. The increase can be attributed to the fact that we are using more threads in parallel to carry out the same task, hence less overall time is needed to carry out the same computation. However, as the number of cores becomes large, the speedup is no longer linearly increasing with number of cores used. This is because there is an associated overhead with communication and synchronization due to the creation and control of threads. As number of cores increases, problem size per core decreases, and these overheads become dominant. This explains the deviation of speedup from the linear trend.
Comparing AWS and Odyssey, Odyssey showed much better performance. We were able to scale to much larger number of cores, allowing for greater speedup, and individual comparable runs were much faster on Odyssey.
Challenges
Big Data
The initial mapping of the continental United States proved more challenging than anticipated. A simple lat-long grid with even increments doesn’t work with the curvature of the earth, thus requiring us to customize a solution on how to scale the longitudes as we moved North.
Once the grid was complete we had to implement several tools not discussed in class to speed-up the mapping coordinates to county time. We had to learn how to use and implement Amazon EMR and GeoSpark to scale our data processing and generate our matrix in a timely manner.
Big Compute
The scale of the problem (updating 3 values for 5,275,648 grid points per time step) was much larger than anything we had encountered before in class. Doing the simulation using data read in for each parameter meant that we were simultaneously handling 14 arrays of size 2944×1792. We had to ensure we did not overflow stack memory and handled as much of the data as possible on heap. This really highlighted the utility of C to us, since we had the power to make these low-level adjustments as required.
Discussion
We were able to use Big Data techniques to create the necessary granular parameter arrays needed for accurate simulation. We were then able to use Big Compute techniques to speedup the large scale simulation that was required. This project really allowed us to use concepts taught in CS205 to solve an ongoing problem in an efficient manner, and we were able to delve into related frameworks outside what was covered.